
I am Yuqing Xie (谢昱清), a 4th year Ph.D. student in the Department of Electronic Engineering, Tsinghua University. Currently, I work in NICS-EFC Lab, supervised by Prof. Yu Wang. From 2018 to 2022, I studied in Xinya College, Tsinghua University. I received my B.E. in Computer Science and Technology and B.A. in Foreign Languages and Literatures in 2022.
My research interests lie in the field of reinforcement learning (RL) and its applications in robotics. More specifically, I am exploring the following topics:
- Robotic control: UAV flight control, robotic arm control;
- RL algorithm: reward shaping, curriculum learning, Sim2Real;
- Large model post-training: RL for LLM and VLA.
Additionally, I contributed to the development of wechaty, OmniDrones, and RLinf.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Tsinghua UniversityDepartment of Electronic Engineering,
Tsinghua UniversityDepartment of Electronic Engineering,
PhD StudentSep. 2022 - present -
Tsinghua UniversityXinya College,
BEng in Computer Science and Technology,
BA in Foreign Languages and LiteraturesSep. 2018 - Jul. 2022
Experience
-
 Infinigence AIResearch InternJun. 2025 - present
Infinigence AIResearch InternJun. 2025 - present -
 Microsoft Research AsiaResearch InternJun. 2021 - Dec. 2021
Microsoft Research AsiaResearch InternJun. 2021 - Dec. 2021
Honors & Awards
-
Tsinghua Graduate Scholarship (First Class)2025
-
Tsinghua Undergraduate Scholarship (top 5%)2021
-
Google Women TechMakers Scholar2020
Selected Publications (view all )
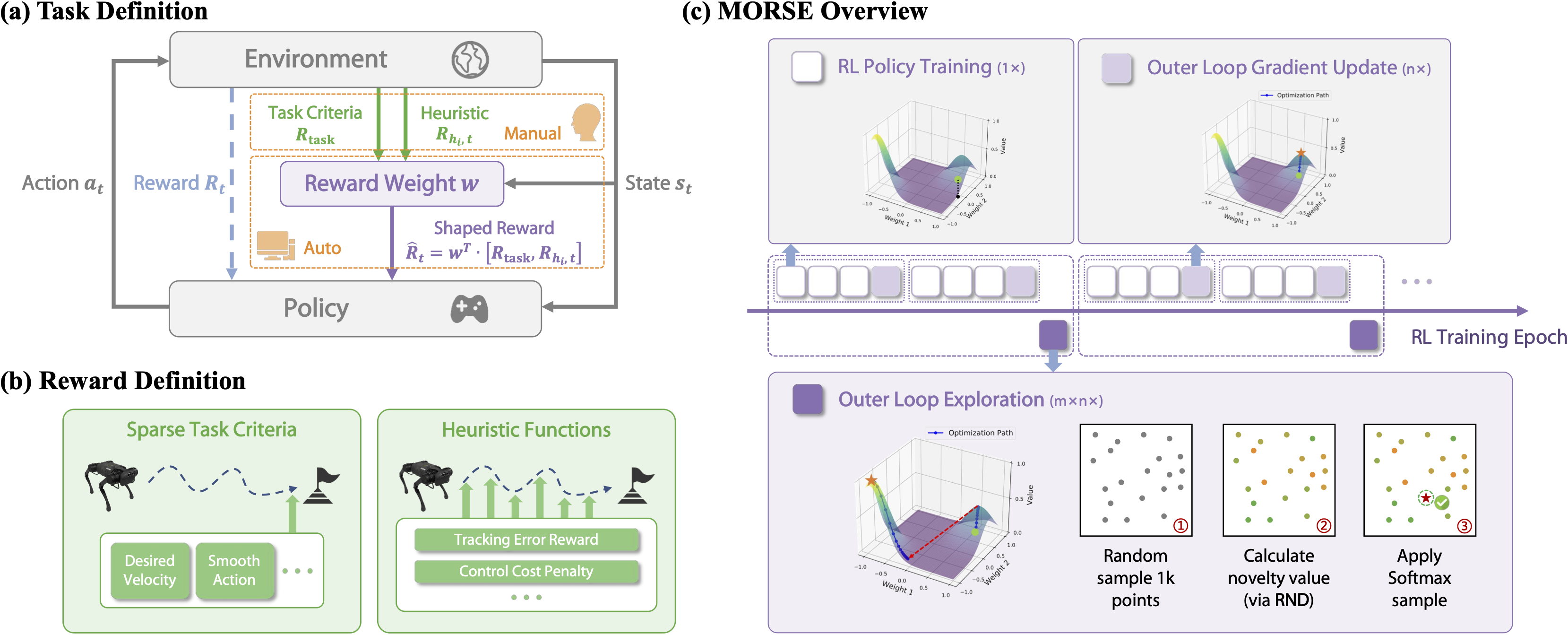
Automatic Reward Shaping from Multi-Objective Human Heuristics
Yuqing Xie, Jiayu Chen, Chao Yu, Yu Wang
NeurIPS 2025 Workshop: Second Workshop on Aligning Reinforcement Learning Experimentalists and Theorists
Submitted to International Conference on Learning Representations (ICLR) 2026. Under review.
We propose Multi-Objective Reward Shaping with Exploration, a general framework that automatically combines multiple human-designed heuristic rewards into a unified reward function. MORSE formulates the shaping process as a bi-level optimization problem: the inner loop trains a policy to maximize the current shaped reward, while the outer loop updates the reward function to optimize task performance. To encourage exploration in the reward space, MORSE introduces stochasticity into the outer-loop optimization.
Automatic Reward Shaping from Multi-Objective Human Heuristics
Yuqing Xie, Jiayu Chen, Chao Yu, Yu Wang
NeurIPS 2025 Workshop: Second Workshop on Aligning Reinforcement Learning Experimentalists and Theorists
Submitted to International Conference on Learning Representations (ICLR) 2026. Under review.
We propose Multi-Objective Reward Shaping with Exploration, a general framework that automatically combines multiple human-designed heuristic rewards into a unified reward function. MORSE formulates the shaping process as a bi-level optimization problem: the inner loop trains a policy to maximize the current shaped reward, while the outer loop updates the reward function to optimize task performance. To encourage exploration in the reward space, MORSE introduces stochasticity into the outer-loop optimization.
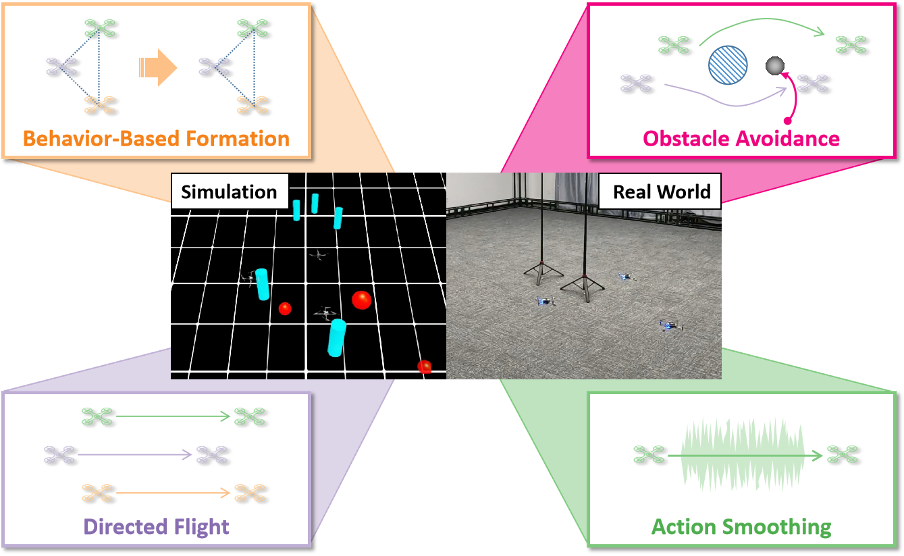
Multi-UAV Formation Control with Static and Dynamic Obstacle Avoidance via Reinforcement Learning
Yuqing Xie*, Chao Yu*, Hongzhi Zang*, Feng Gao, Wenhao Tang, Jingyi Huang, Jiayu Chen, Botian Xu, Yi Wu, Yu Wang (* equal contribution)
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2025
We require multiple UAVs to (1) maintain formation; (2) avoid both static and dynamic obstacles; (3) follow velocity commands; (4) perform smooth actions. To tackle the 4-objective task, we propose a 2-stage RL training pipeline.
Multi-UAV Formation Control with Static and Dynamic Obstacle Avoidance via Reinforcement Learning
Yuqing Xie*, Chao Yu*, Hongzhi Zang*, Feng Gao, Wenhao Tang, Jingyi Huang, Jiayu Chen, Botian Xu, Yi Wu, Yu Wang (* equal contribution)
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2025
We require multiple UAVs to (1) maintain formation; (2) avoid both static and dynamic obstacles; (3) follow velocity commands; (4) perform smooth actions. To tackle the 4-objective task, we propose a 2-stage RL training pipeline.