2025
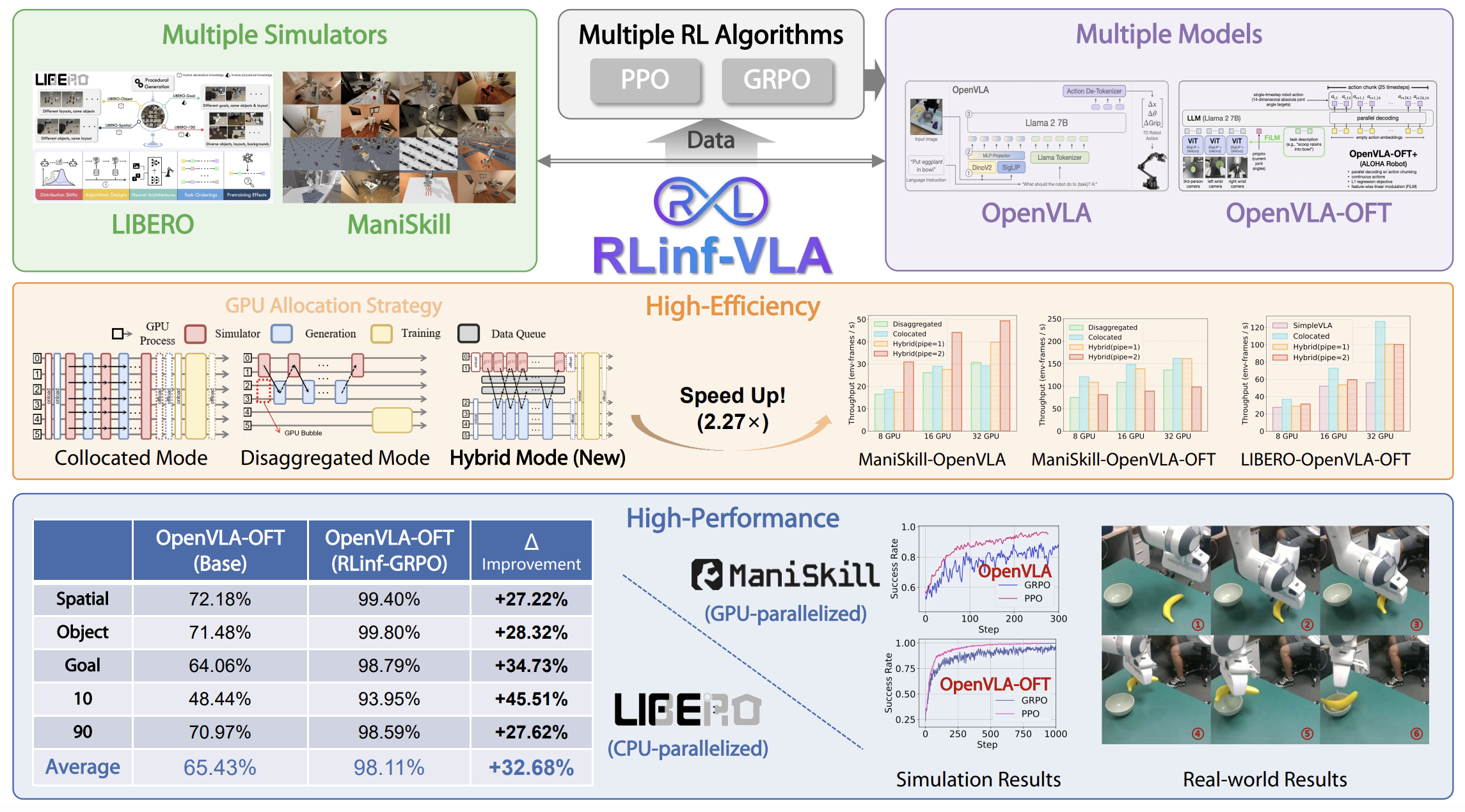
RLinf-VLA: A Unified and Efficient Framework for VLA+RL Training
Hongzhi Zang, Mingjie Wei, Si Xu, Yongji Wu, Zhen Guo, Yuanqing Wang, Hao Lin, Liangzhi Shi, Yuqing Xie, Zhexuan Xu, Zhihao Liu, Kang Chen, Wenhao Tang, Quanlu Zhang, Weinan Zhang, Chao Yu, Yu Wang
arxiv 2025
We introduce RLinf-VLA, a unified and efficient framework for scalable RL training of VLA models. The system adopts a highly flexible resource allocation design that addresses the challenge of integrating rendering, training, and inference in RL+VLA training.
RLinf-VLA: A Unified and Efficient Framework for VLA+RL Training
Hongzhi Zang, Mingjie Wei, Si Xu, Yongji Wu, Zhen Guo, Yuanqing Wang, Hao Lin, Liangzhi Shi, Yuqing Xie, Zhexuan Xu, Zhihao Liu, Kang Chen, Wenhao Tang, Quanlu Zhang, Weinan Zhang, Chao Yu, Yu Wang
arxiv 2025
We introduce RLinf-VLA, a unified and efficient framework for scalable RL training of VLA models. The system adopts a highly flexible resource allocation design that addresses the challenge of integrating rendering, training, and inference in RL+VLA training.
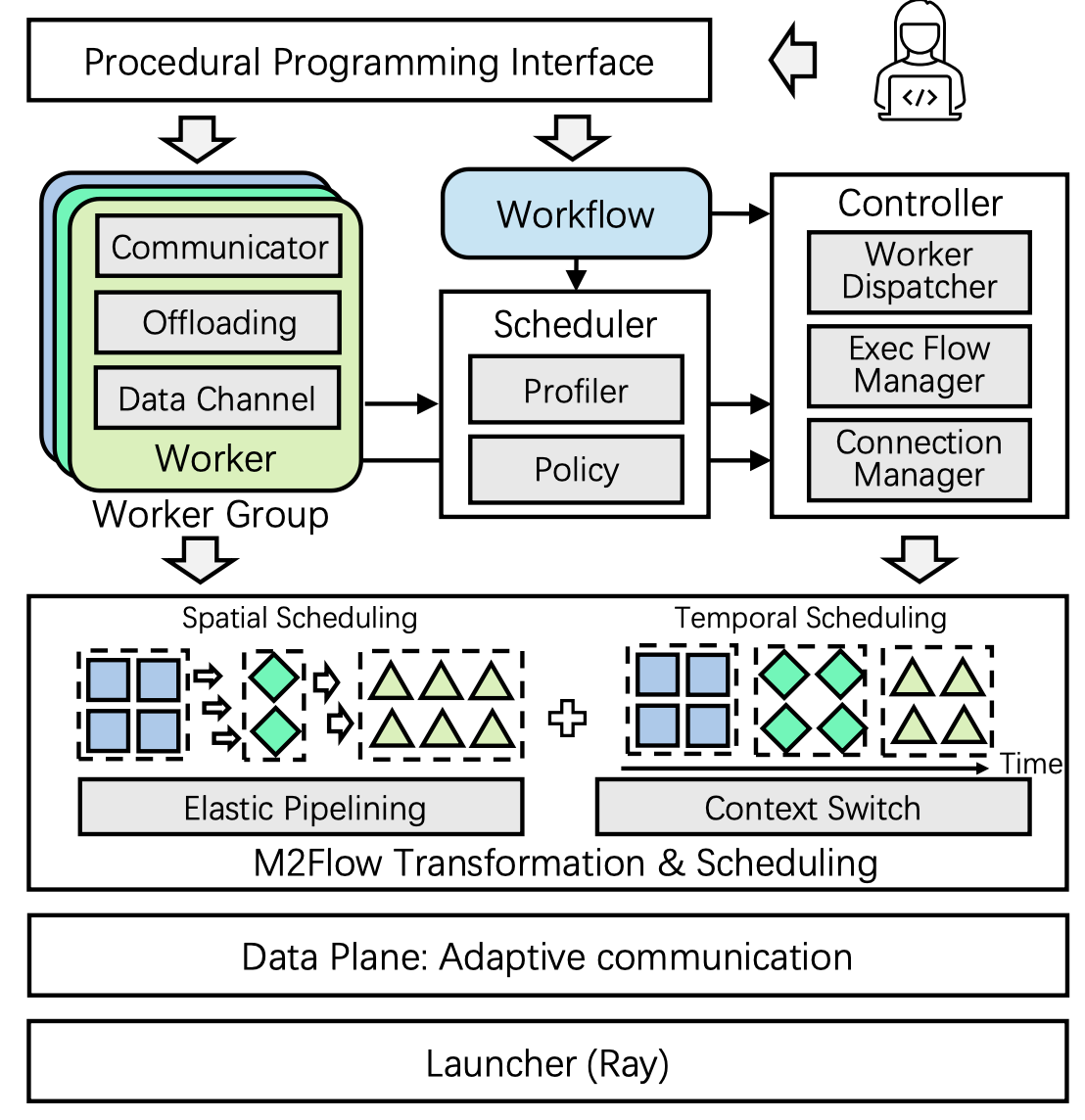
RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
Chao Yu, Yuanqing Wang, Zhen Guo, Hao Lin, Si Xu, Hongzhi Zang, Quanlu Zhang, Yongji Wu, Chunyang Zhu, Junhao Hu, Zixiao Huang, Mingjie Wei, Yuqing Xie, Ke Yang, Bo Dai, Zhexuan Xu, Xiangyuan Wang, Xu Fu, Zhihao Liu, Kang Chen, Weilin Liu, Gang Liu, Boxun Li, Jianlei Yang, Zhi Yang, Guohao Dai, Yu Wang
Submitted to USENIX Symposium on Operating Systems Design and Implementation (OSDI) 2026 Under review.
We present RLinf, a high-performance RL training system. To maximize flexibility and efficiency, RLinf is built atop a novel RL system design paradigm called macro-to-micro flow transformation (M2Flow), which automatically breaks down high-level RL workflows and recomposes them into optimized execution flows.
RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
Chao Yu, Yuanqing Wang, Zhen Guo, Hao Lin, Si Xu, Hongzhi Zang, Quanlu Zhang, Yongji Wu, Chunyang Zhu, Junhao Hu, Zixiao Huang, Mingjie Wei, Yuqing Xie, Ke Yang, Bo Dai, Zhexuan Xu, Xiangyuan Wang, Xu Fu, Zhihao Liu, Kang Chen, Weilin Liu, Gang Liu, Boxun Li, Jianlei Yang, Zhi Yang, Guohao Dai, Yu Wang
Submitted to USENIX Symposium on Operating Systems Design and Implementation (OSDI) 2026 Under review.
We present RLinf, a high-performance RL training system. To maximize flexibility and efficiency, RLinf is built atop a novel RL system design paradigm called macro-to-micro flow transformation (M2Flow), which automatically breaks down high-level RL workflows and recomposes them into optimized execution flows.
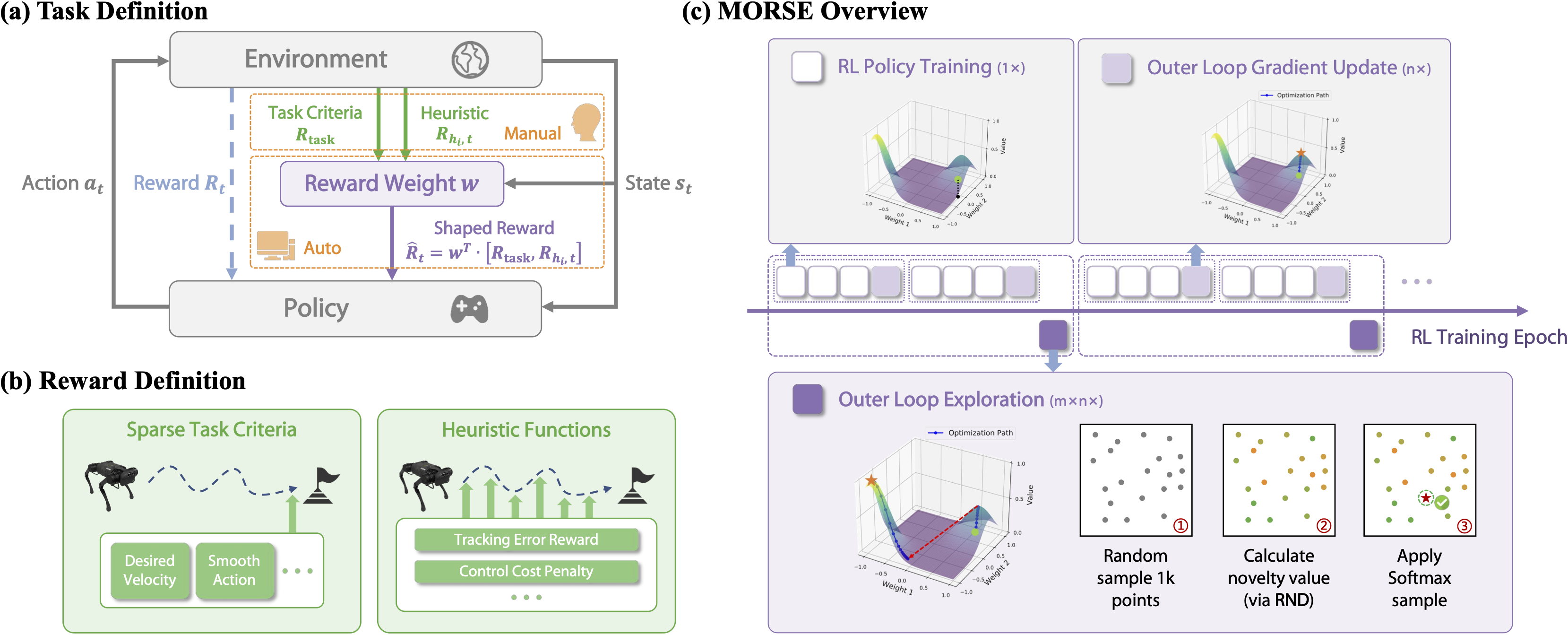
Automatic Reward Shaping from Multi-Objective Human Heuristics
Yuqing Xie, Jiayu Chen, Wenhao Tang, Ya Zhang, Chao Yu, Yu Wang
NeurIPS 2025 Workshop: Second Workshop on Aligning Reinforcement Learning Experimentalists and Theorists
Submitted to International Conference on Learning Representations (ICLR) 2026. Under review.
We propose Multi-Objective Reward Shaping with Exploration, a general framework that automatically combines multiple human-designed heuristic rewards into a unified reward function. MORSE formulates the shaping process as a bi-level optimization problem: the inner loop trains a policy to maximize the current shaped reward, while the outer loop updates the reward function to optimize task performance. To encourage exploration in the reward space, MORSE introduces stochasticity into the outer-loop optimization.
Automatic Reward Shaping from Multi-Objective Human Heuristics
Yuqing Xie, Jiayu Chen, Wenhao Tang, Ya Zhang, Chao Yu, Yu Wang
NeurIPS 2025 Workshop: Second Workshop on Aligning Reinforcement Learning Experimentalists and Theorists
Submitted to International Conference on Learning Representations (ICLR) 2026. Under review.
We propose Multi-Objective Reward Shaping with Exploration, a general framework that automatically combines multiple human-designed heuristic rewards into a unified reward function. MORSE formulates the shaping process as a bi-level optimization problem: the inner loop trains a policy to maximize the current shaped reward, while the outer loop updates the reward function to optimize task performance. To encourage exploration in the reward space, MORSE introduces stochasticity into the outer-loop optimization.
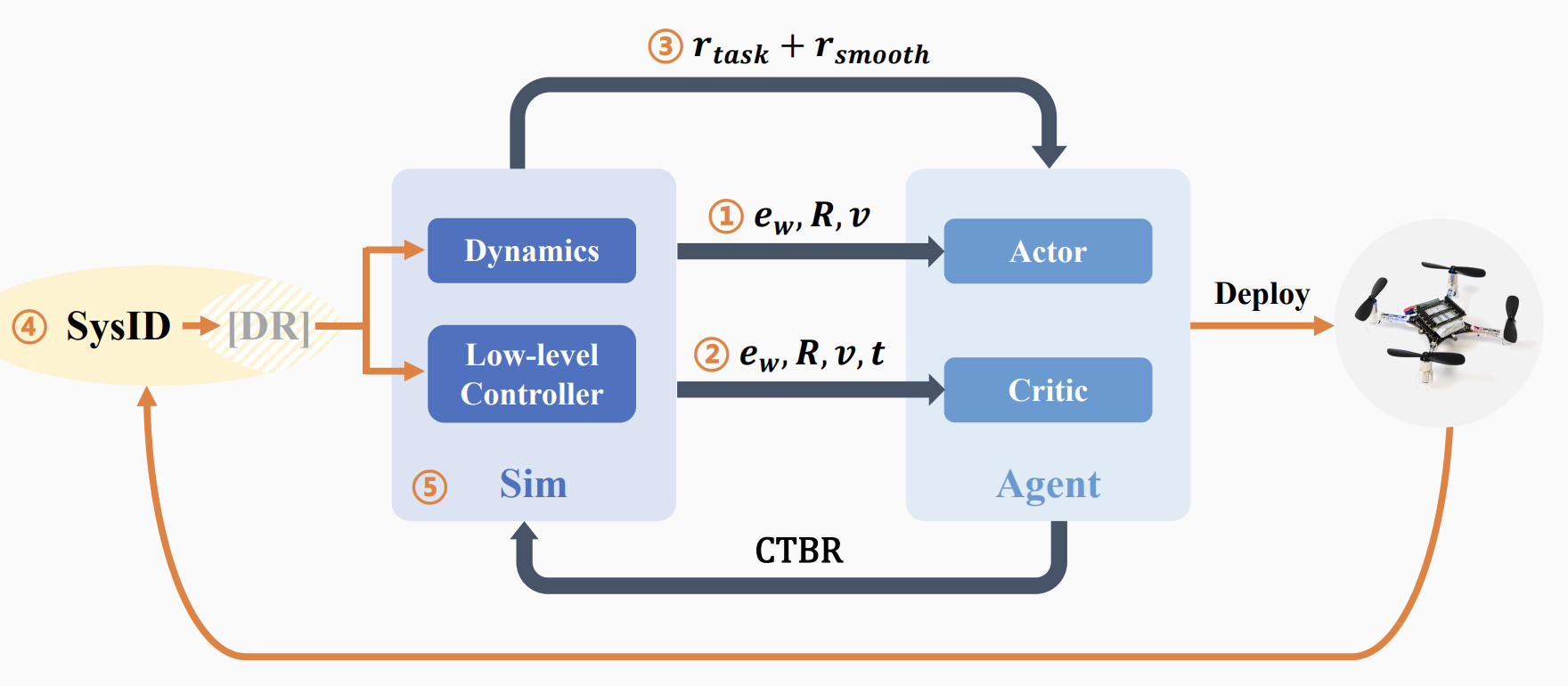
What Matters in Learning A Zero-Shot Sim-to-Real RL Policy for Quadrotor Control? A Comprehensive Study
Jiayu Chen*, Chao Yu*, Yuqing Xie, Feng Gao, Yinuo Chen, Shu'ang Yu, Wenhao Tang, Shilong Ji, Mo Mu, Yi Wu, Huazhong Yang, Yu Wang (* equal contribution)
IEEE Robotics and Automation Letters (R-AL) 2025
Also presented at International Conference on Robotics and Automation (ICRA) 2026
We identify five key factors for learning robust RL-based control policies capable of zero-shot real-world deployment and develop SimpleFlight, a PPO-based framework that integrates these techniques.
What Matters in Learning A Zero-Shot Sim-to-Real RL Policy for Quadrotor Control? A Comprehensive Study
Jiayu Chen*, Chao Yu*, Yuqing Xie, Feng Gao, Yinuo Chen, Shu'ang Yu, Wenhao Tang, Shilong Ji, Mo Mu, Yi Wu, Huazhong Yang, Yu Wang (* equal contribution)
IEEE Robotics and Automation Letters (R-AL) 2025
Also presented at International Conference on Robotics and Automation (ICRA) 2026
We identify five key factors for learning robust RL-based control policies capable of zero-shot real-world deployment and develop SimpleFlight, a PPO-based framework that integrates these techniques.
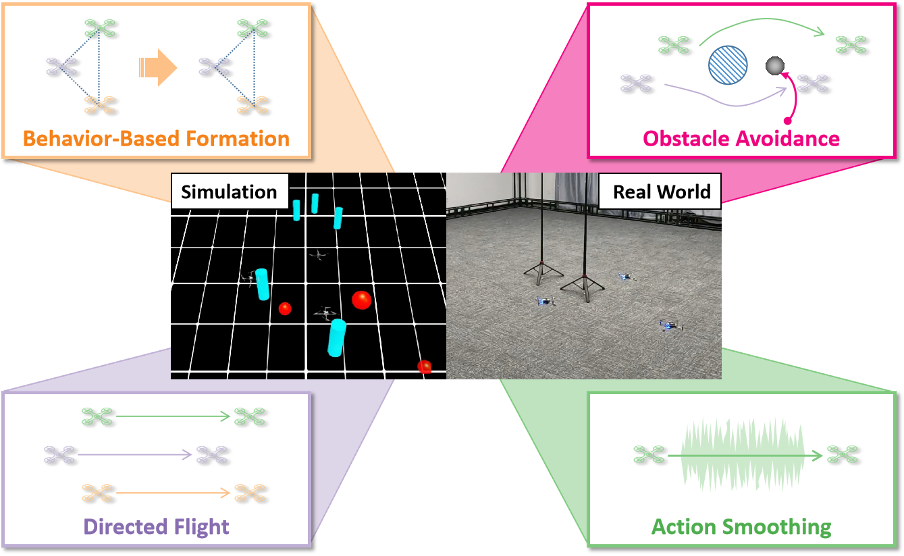
Multi-UAV Formation Control with Static and Dynamic Obstacle Avoidance via Reinforcement Learning
Yuqing Xie*, Chao Yu*, Hongzhi Zang*, Feng Gao, Wenhao Tang, Jingyi Huang, Jiayu Chen, Botian Xu, Yi Wu, Yu Wang (* equal contribution)
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2025
We require multiple UAVs to (1) maintain formation; (2) avoid both static and dynamic obstacles; (3) follow velocity commands; (4) perform smooth actions. To tackle the 4-objective task, we propose a 2-stage RL training pipeline.
Multi-UAV Formation Control with Static and Dynamic Obstacle Avoidance via Reinforcement Learning
Yuqing Xie*, Chao Yu*, Hongzhi Zang*, Feng Gao, Wenhao Tang, Jingyi Huang, Jiayu Chen, Botian Xu, Yi Wu, Yu Wang (* equal contribution)
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2025
We require multiple UAVs to (1) maintain formation; (2) avoid both static and dynamic obstacles; (3) follow velocity commands; (4) perform smooth actions. To tackle the 4-objective task, we propose a 2-stage RL training pipeline.
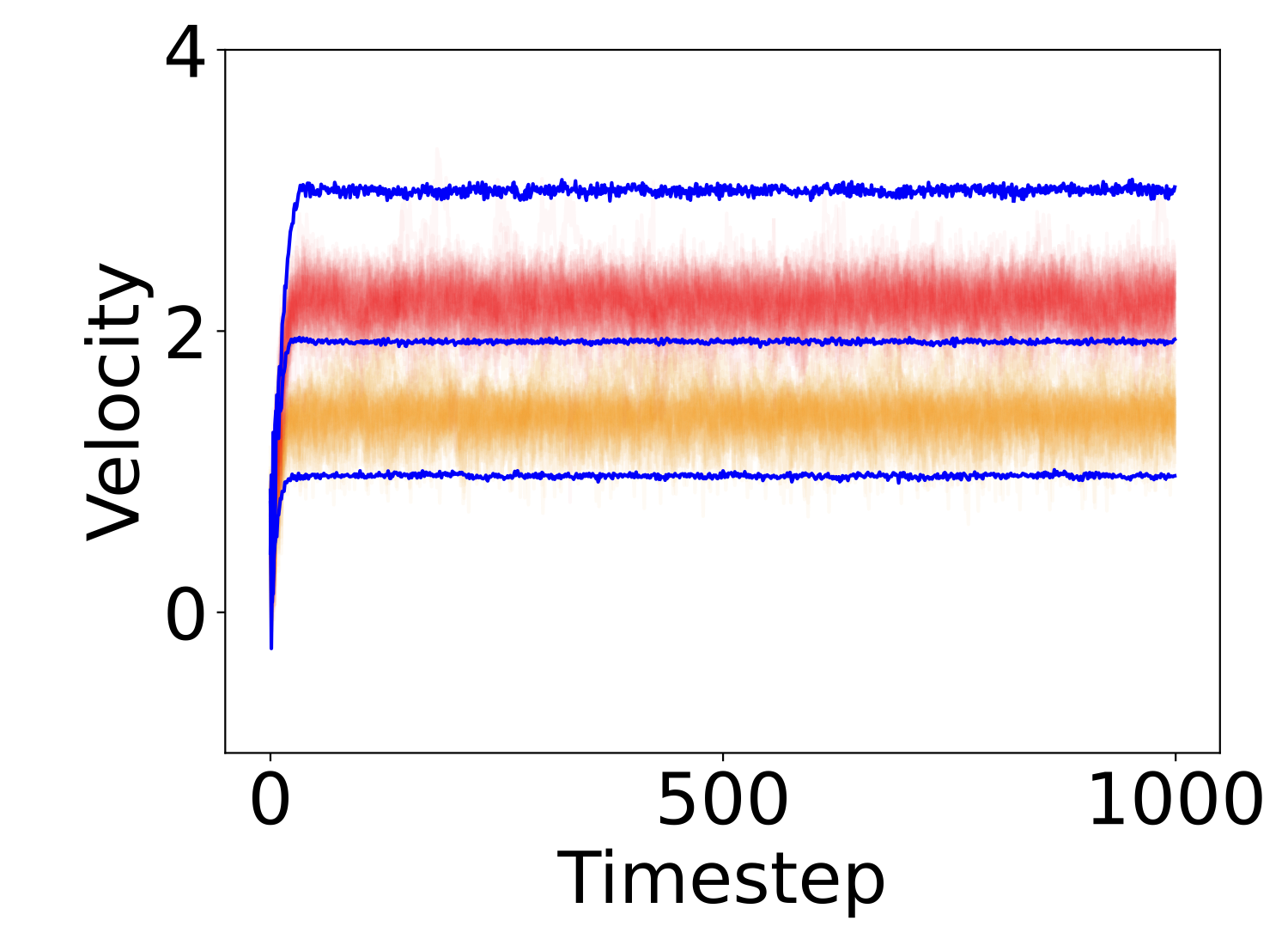
An Empirical Study of Policy Interpolation via Diffusion Models
Yuqing Xie, Chao Yu, Ya Zhang, Yu Wang
ICLR 2025 Workshop on Modularity for Collaborative, Decentralized, and Continual Deep Learning (MCDC)
We explore the inference-time composition of diffusion-based policies using various interpolation methods.
An Empirical Study of Policy Interpolation via Diffusion Models
Yuqing Xie, Chao Yu, Ya Zhang, Yu Wang
ICLR 2025 Workshop on Modularity for Collaborative, Decentralized, and Continual Deep Learning (MCDC)
We explore the inference-time composition of diffusion-based policies using various interpolation methods.
2024
LLM-Powered Hierarchical Language Agent for Real-time Human-AI Coordination
Jijia Liu*, Chao Yu*, Jiaxuan Gao*, Yuqing Xie, Qingmin Liao, Yi Wu, Yu Wang (* equal contribution)
International Conference on Autonomous Agents and Multiagent Systems (AAMAS) 2024
We propose a Hierarchical Language Agent (HLA) for human-AI coordination that provides strong reasoning ability while keeping real-time execution. Human studies show that HLA outperforms other baseline agents with stronger cooperation abilities, faster responses, and more consistent language communications.
LLM-Powered Hierarchical Language Agent for Real-time Human-AI Coordination
Jijia Liu*, Chao Yu*, Jiaxuan Gao*, Yuqing Xie, Qingmin Liao, Yi Wu, Yu Wang (* equal contribution)
International Conference on Autonomous Agents and Multiagent Systems (AAMAS) 2024
We propose a Hierarchical Language Agent (HLA) for human-AI coordination that provides strong reasoning ability while keeping real-time execution. Human studies show that HLA outperforms other baseline agents with stronger cooperation abilities, faster responses, and more consistent language communications.
2023
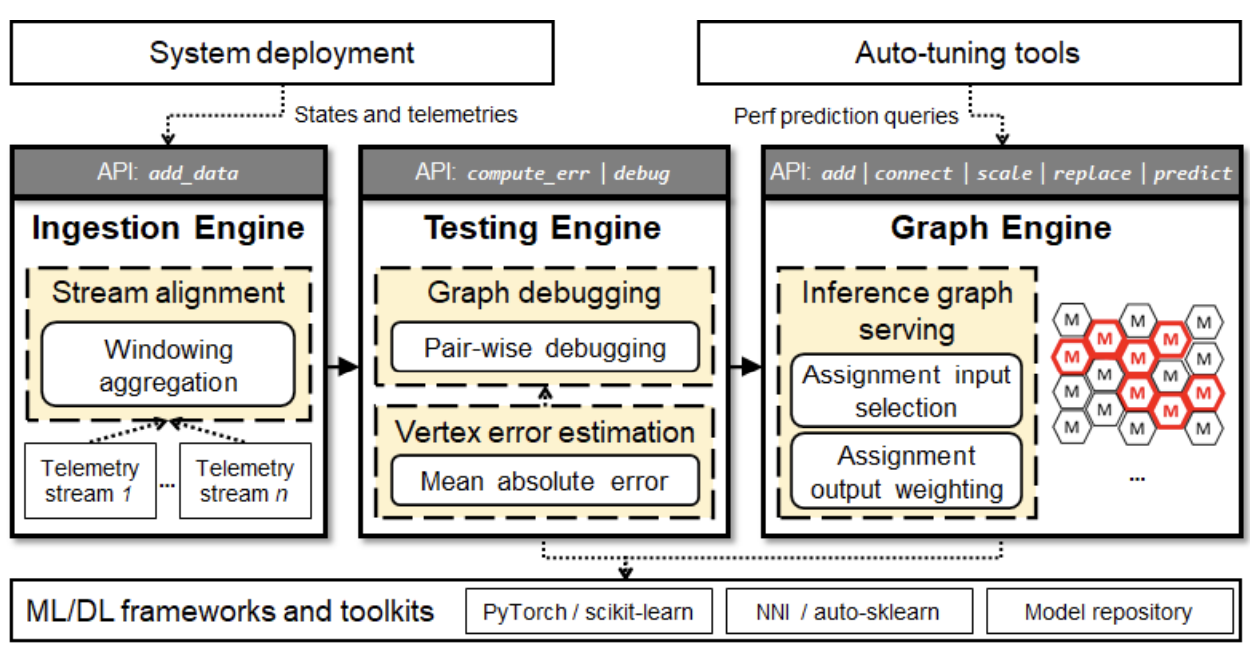
On Modular Learning of Distributed Systems for Predicting End-to-End Latency
Chieh-Jan Mike Liang, Zilin Fang, Yuqing Xie, Fan Yang, Zhao Lucis Li, Li Lyna Zhang, Mao Yang, Lidong Zhou
USENIX Symposium on Networked Systems Design and Implementation (NSDI) 2023
We propose Fluxion, a framework to model end-to-end system latency with modularized learning. Fluxion introduces learning assignment, a new abstraction that allows modeling individual sub-components. With a consistent interface, multiple learning assignments can be dynamically composed into an inference graph, to model a complex distributed system on the fly.
On Modular Learning of Distributed Systems for Predicting End-to-End Latency
Chieh-Jan Mike Liang, Zilin Fang, Yuqing Xie, Fan Yang, Zhao Lucis Li, Li Lyna Zhang, Mao Yang, Lidong Zhou
USENIX Symposium on Networked Systems Design and Implementation (NSDI) 2023
We propose Fluxion, a framework to model end-to-end system latency with modularized learning. Fluxion introduces learning assignment, a new abstraction that allows modeling individual sub-components. With a consistent interface, multiple learning assignments can be dynamically composed into an inference graph, to model a complex distributed system on the fly.