文献综述:AlphaGo系列文章调研
摘要
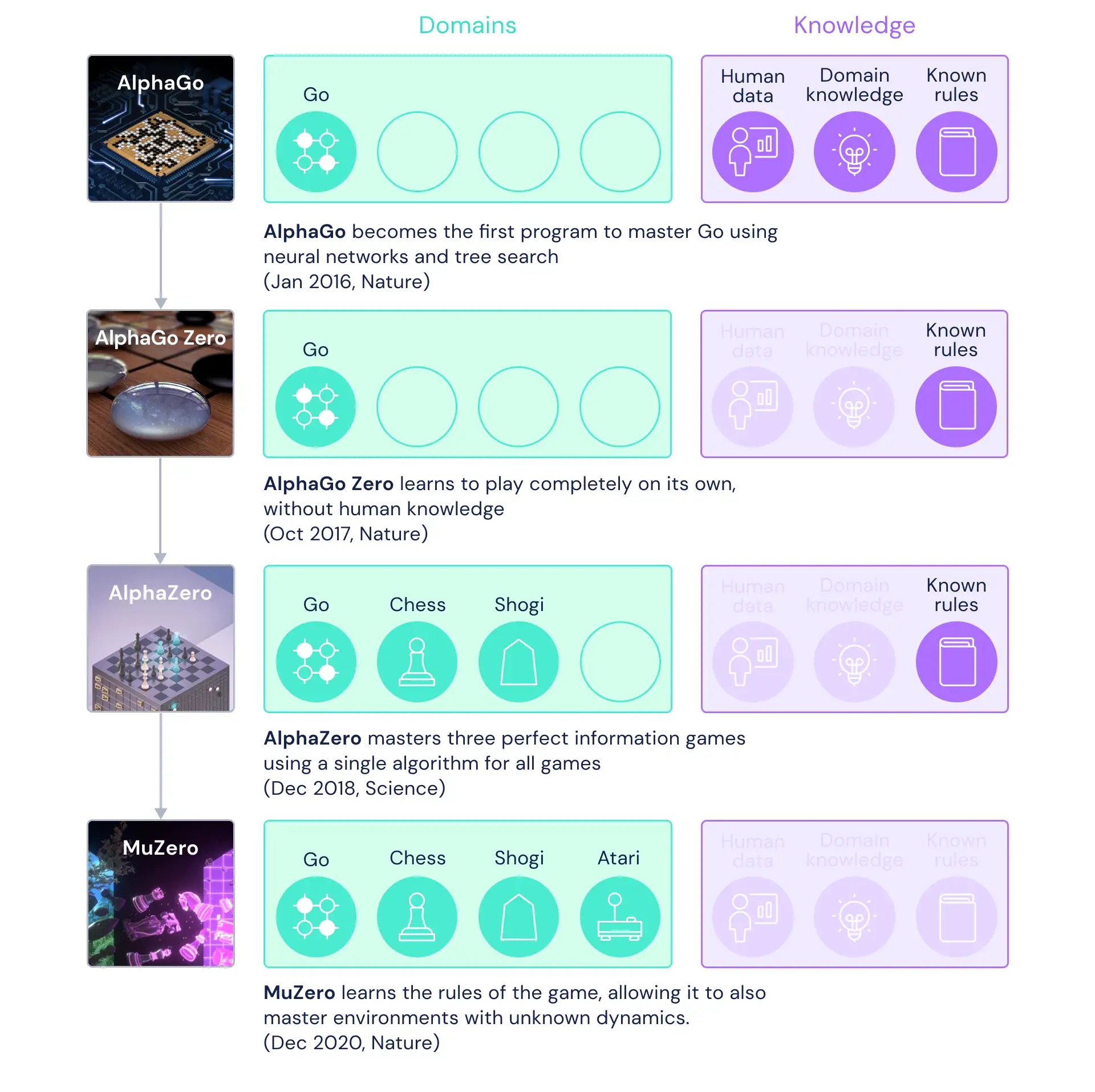
作为第一次击败顶级人类围棋玩家的AI,AlphaGo一经问世便颠覆了人们对于人工智能的固有认知。在此之后,AlphaGo逐渐脱离了围棋规则的限制,可以求解更加一般、更加通用的场景,最终演化为了MuZero。在MuZero问世后,部分研究者致力于优化AlphaGo的算力,提升AlphaGo的运算速度;同时,一些学者也在探究如何拓展AlphaGo到更多的现实应用中。本综述将围绕AlphaGo系列文章展开,先介绍AlphaGo的框架以及AlphaGo到MuZero的衍化,再介绍MuZero后的性能提升,最后着眼于AlphaGo的应用。
AlphaGo
AlphaGo 主要分为两部分: 一部分是 Monte-Carlo 树搜索的变种,另一部分是评估价值与策略的参数网络。网络通过有监督学习从人类专家数据中提取特征,之后通过强化学习与自我对弈提升。Monte-Carlo 树搜索使用策略网络仿真,并通过价值网络评估节点的价值。
Monte-Carlo树搜索
Monte-Carlo树搜索(MCTS)算法主要分为四个部分:
- 通过一定方式选择一个可扩展节点$n_0$。
- 执行动作拓展$n_0$得到$n_1$。
- 使用蒙特卡洛方式(即随机模拟)在$n_1$处模拟棋局,对应奖励。
- 回溯更新各祖先节点价值。
重复上述过程后,AI选择胜率或其他指标最大的节点落子。
MCTS算法核心的几点如下:
- 节点选择:如UCT算法,
- 节点扩展后,从新节点模拟获得奖励。
- 回溯更新,如 $N(v)\leftarrow N(v)+1$, $Q(v)\leftarrow Q(v)+\Delta$。
选择子节点时,既要考虑访问次数,也要关注价值高低。实际如AlphaGo系列还有诸多改进。
网络训练
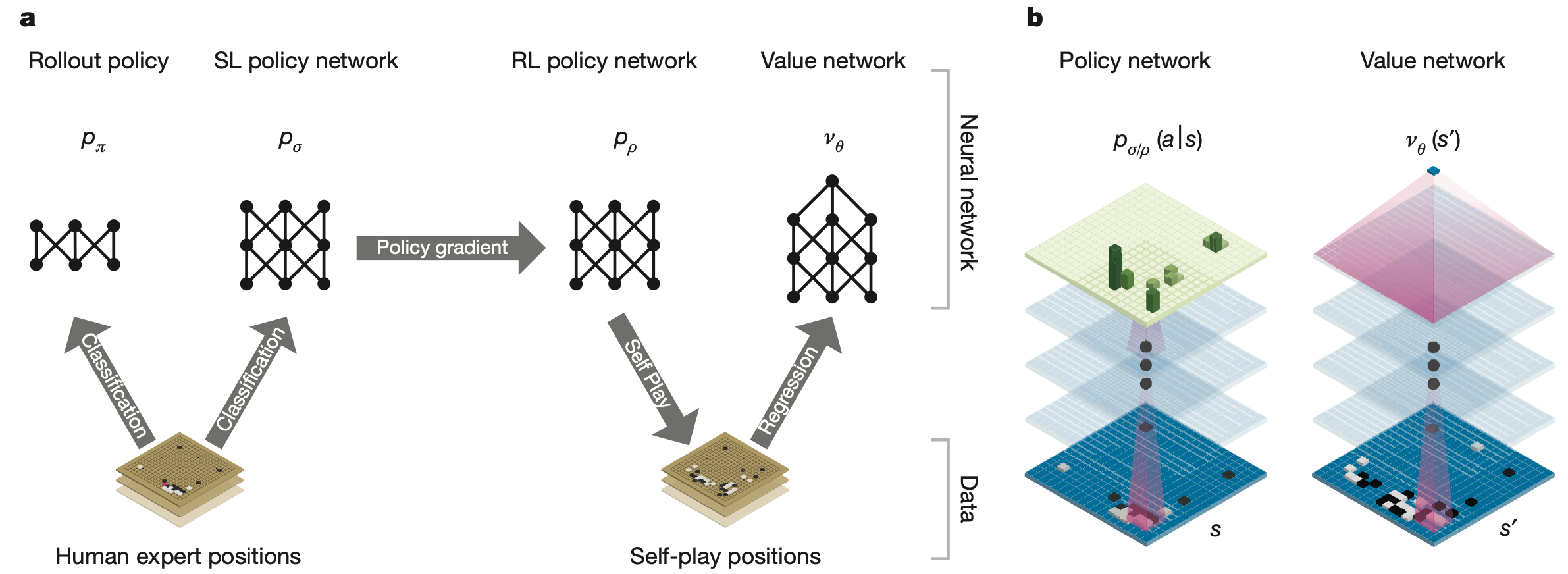
在训练阶段,AlphaGo 需要学习价值网络和策略网络,主要过程:
- 从大规模人类专家数据集中(约3000万人棋谱),使用有监督学习得到快速仿真策略$\pi_\delta$,和复杂策略$\pi_\sigma$。
- $\pi_\sigma$通过自我对弈和策略梯度进化为强化学习策略$\pi_\rho$。
- 用$\pi_\rho$进行自我对弈,得到若干棋局和值,训练神经网络$V_\theta$评估棋局。
$V_\theta$在同一状态上的预测效果接近多次仿真,推理更快。
MCTS对弈流程与改进
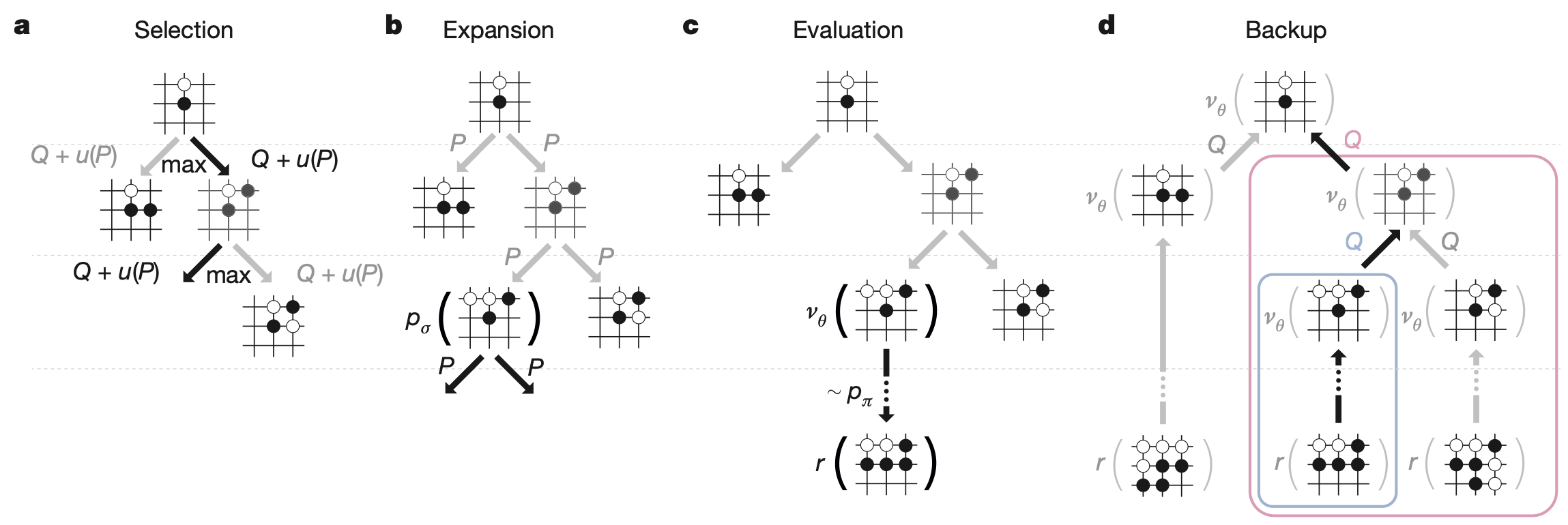
在实际对弈阶段,AlphaGo采用改进版MCTS按以下方式落子:
- 节点选择方式:
其中 $u(s, a) \propto \frac{\pi_\sigma(a|s)}{1+N(s,a)}$,$\pi_\sigma$为网络先验概率。
- 节点扩展与仿真同时结合价值网络$V_\theta$与简单仿真。
- 回溯更新时按节点均值。
树搜索结束后,选择访问次数最多的动作。
AlphaGo Zero
AlphaGo Zero的主要特征:
- 完全从0自我对弈,参数随机初始化,不依赖人类/专家数据。
- 状态特征=黑白子布局,无其他人工设计特征。
- 策略网络与价值网络由统一残差骨干输出。
- 搜索轨迹直接用策略网络,无需仿真。
训练时更强调网络输出与MCTS结果一致。
AlphaZero
- 不依赖任何棋类规则和专家数据,可直接迁移到象棋、将棋等。
- 针对特定棋类实现细小调整,如平局支持、去除棋局旋转增强。
- 网络参数持续更新,非冻结策略。
MuZero
- 核心创新是模型组件,自动学习环境变化和奖励,而并非显式给定规则。
- 在围棋、象棋、Atari等多任务下表现优秀。
- 先对观测$o_{1:t}$编码得到隐空间$s_t$,在隐空间内MCTS规划,预测策略$p_t$与价值$v_t$,用模型网络预测$(s_{t+1}, r_t)$。
- 强调仅学对规划有用的动态,无需完全复现环境。
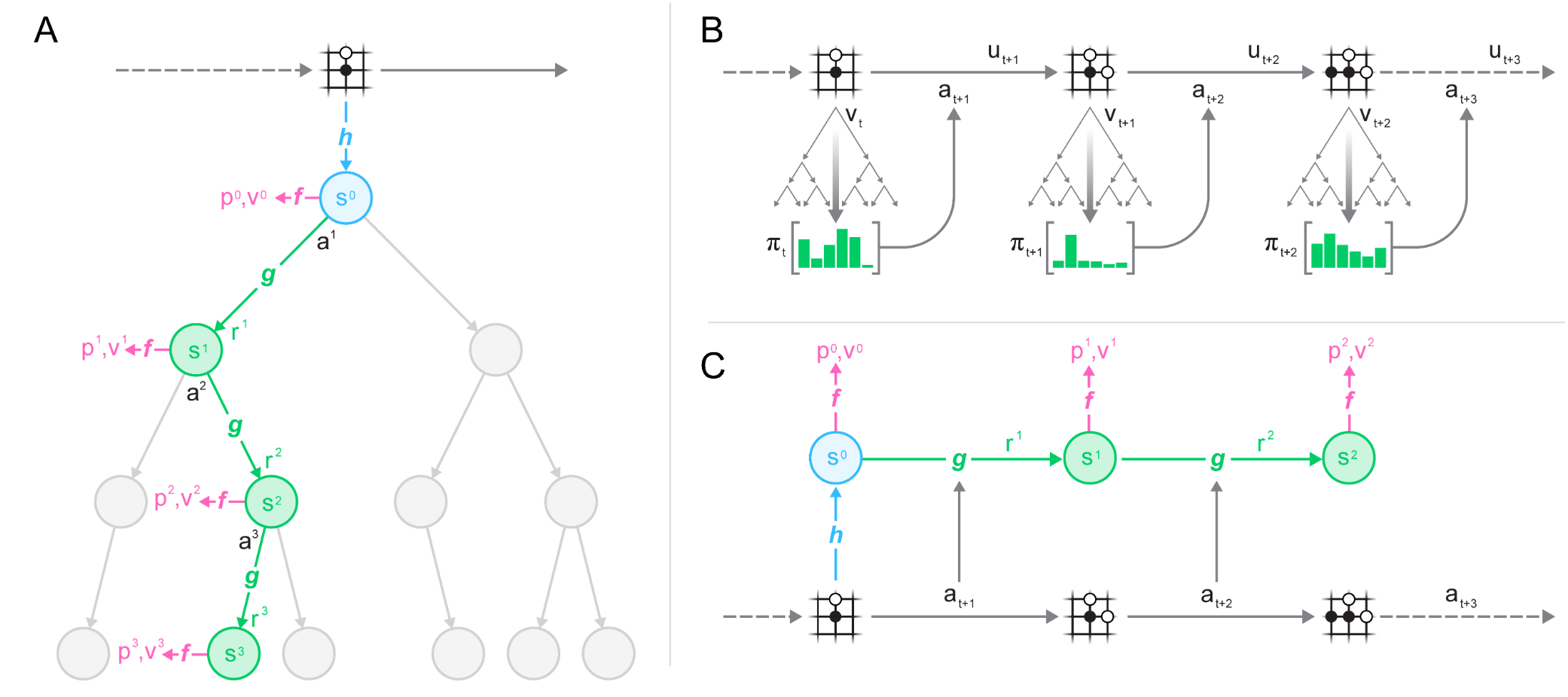
MuZero改进
MuZero Unplugged
MuZero Unplugged 引入 Reanalyse 算法,从而将 MuZero 拓展到兼顾在线与离线的 RL 场景。其主要思想:
- 用最新模型参数在离线数据上重新执行MCTS,不直接与环境交互。
- 通过调节 Reanalyse 比例实现在线/离线数据权衡,提高数据利用率。
- 在 Atari、DM Control Suite 等均优于传统方法。

EfficientZero
EfficientZero 针对数据稀缺和训练时长的问题提出:
- 加入自监督损失,强迫模型状态预测短期保持一致性。
- 直接学习价值前缀(非逐步奖励),抑制 compounding error。
- 用模型纠正离线策略目标,数据稀缺时缓解 off-policy 问题。
相较其他算法能更快、更高分学会 Atari 游戏。
SpeedyZero
SpeedyZero 将 EfficientZero 分布式化,达到同等表现下更快训练:
- 系统设计优化分配通信与存储,提升线程/GPU 利用。
- 算法层面引入 priority refresh 和 Clipped LARS 提升收敛。
这些工作共同推动了大规模 RL 系统的数据和算力效率。
AlphaZero的应用
分子合成
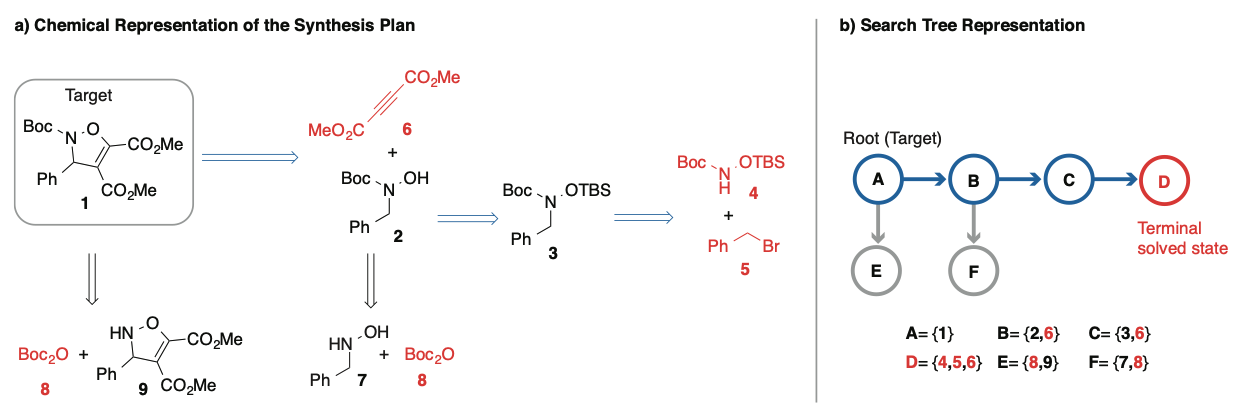
将 AlphaGo/MCTS 结合用于分子合成路径规划:
- 状态为分子的当前结构,动作为可用化学反应规则。
- 目标:找到所有子产物都为工业可用原料的反应序列。
算法结合了专家数据训练快速策略和价值网络评估。
AlphaTensor(矩阵乘优化)
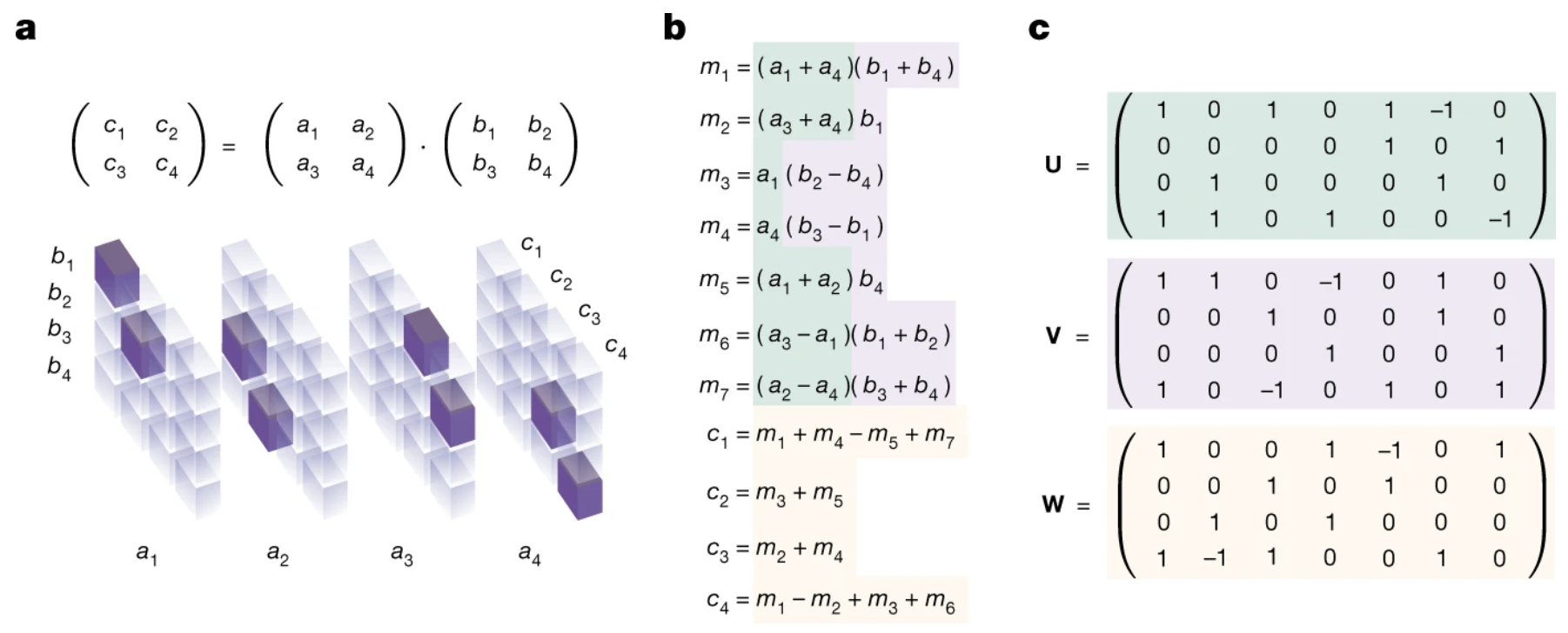
AlphaTensor 利用 RL、搜索和 Transformer 结构,发现在更高维度下更快的矩阵乘法方案。
- 状态为当前张量,动作为选取的分解向量。
- 奖励:完成用的步数越少得分越高,超时按秩罚分。
- 架构扩展到数据增强与性质推理。
AlphaDev(排序/哈希优化)
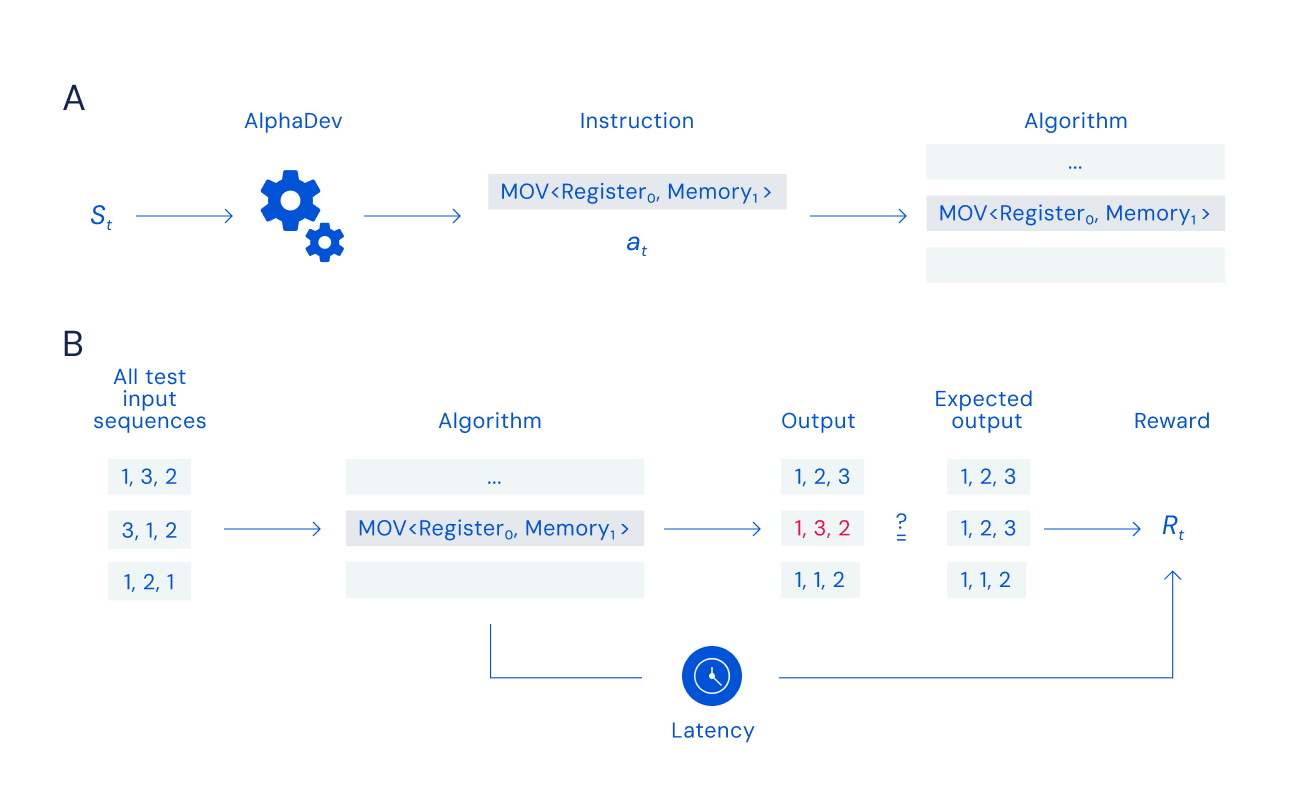
AlphaDev 直接操作底层汇编指令寻找新的排序算法:
- 状态:当前算法+CPU信息。
- 动作:一条汇编指令。
- 奖励:能否正确排序与所用时间。
新解比开源算法快1.7%~70%,同理提升了哈希算法。
总结与展望
AlphaGo系列算法极大拓展了RL和搜索算法的理论与应用边界。今后值得关注方向包括:
- 更强性能:包括分布式平台、架构创新(如Transformer等)。
- 更通用/泛化算法:如连续空间、多智能体、多纳什均衡等。
- 更广泛落地:将RL+MCTS思想应用于实际问题,如资源分配、分子设计、自动代码优化等。
主要参考文献
- Silver et al., 2016. Mastering the game of Go with deep neural networks and tree search. Nature.
- Silver et al., 2017. Mastering the game of go without human knowledge. Nature.
- Silver et al., 2018. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science.
- Schrittwieser et al., 2020. Mastering Atari, Go, chess and shogi by planning with a learned model. Nature. (MuZero)
- Fawzi et al., 2022. Discovering faster matrix multiplication algorithms with reinforcement learning. Nature. (AlphaTensor)
- Mankowitz et al., 2023. Faster sorting algorithms discovered using deep reinforcement learning. Nature. (AlphaDev)
- Segler et al., 2018. Planning chemical syntheses with deep neural networks and symbolic AI. Nature.